


Маунтин-Вью, США. Google Research 30 июня представила TabFM — фундаментальную модель для классификации и регрессии на табличных данных. Модель может работать с новой таблицей без отдельного обучения её весов, ручного проектирования признаков и перебора гиперпараметров, говорится в сообщении исследовательского подразделения Google.
Это не означает, что TabFM «никогда не училась». Модель заранее обучили на сотнях миллионов синтетических наборов данных. Слово zero-shot в данном случае означает другое: при переходе к конкретной таблице параметры модели не обновляются. Размеченные примеры передаются ей прямо во время инференса и становятся контекстом для прогноза.
Почему таблицы остаются сложной задачей для ИИ
Продажи, заявки клиентов, транзакции, складские остатки и результаты обследований обычно хранятся не как текст или изображения, а в строках и столбцах. Для таких данных десятилетиями применяются градиентный бустинг, случайные леса и другие специализированные алгоритмы.
Классический проект требует выбрать признаки, обработать пропуски и категории, обучить несколько вариантов модели, подобрать настройки и проверить их на отложенной выборке. TabFM пытается сократить этот цикл: одна предварительно обученная модель должна распознать закономерность новой задачи по примерам, которые ей показали вместе с неизвестными строками.
| Этап | Обычный табличный ML | TabFM |
|---|---|---|
| Подготовка задачи | Отдельный пайплайн для каждого набора | Обучающие строки передаются как контекст |
| Параметры модели | Обновляются при обучении | Не меняются на новой таблице |
| Настройка | Часто нужен поиск гиперпараметров | Базовый режим — один прямой проход |
| Проверка качества | Обязательна | Также обязательна |
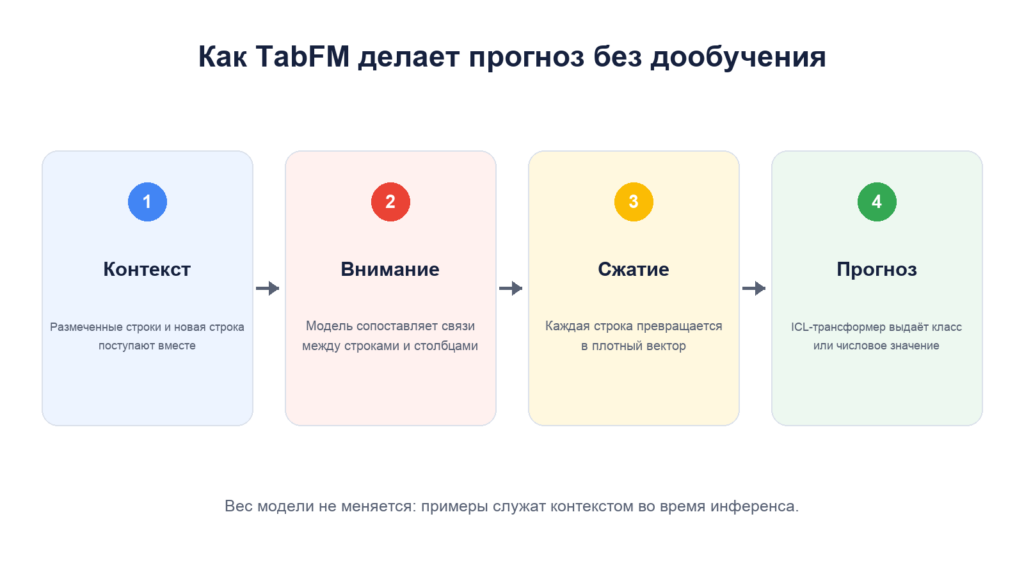
Как модель читает строки и столбцы
TabFM получает размеченную часть таблицы и строки, для которых нужен ответ, как единый ввод. Первый блок архитектуры попеременно применяет внимание по столбцам и строкам: модель ищет связи между признаками и сравнивает примеры между собой.
Затем информация каждой строки сжимается в плотное векторное представление. Последний блок — причинный ICL-трансформер из 24 слоёв — работает уже с последовательностью этих векторов и выдаёт класс или числовое значение. По данным карточки TabFM 1.0.0, архитектура поддерживает числовые и категориальные столбцы.
В совместимом со scikit-learn интерфейсе по-прежнему используется метод fit(), что может сбить с толку. Однако официальный репозиторий TabFM поясняет: этот вызов подготавливает кодировщики категорий и масштабирующие преобразования, а не переобучает параметры фундаментальной модели.
Почему обучение прошло на синтетических таблицах
Для текстовых и визуальных моделей доступны огромные открытые коллекции, тогда как промышленные таблицы часто содержат коммерческие схемы и персональные данные. Google обошла этот дефицит, динамически генерируя сотни миллионов синтетических наборов с помощью структурных причинных моделей.
Такой подход позволяет показать модели множество зависимостей между признаками, не используя реальные клиентские базы. Но это одновременно источник неопределённости: синтетический мир не гарантирует полного совпадения с редкими событиями, изменением поведения пользователей или смещениями в конкретной отрасли.
Что показал рейтинг TabArena
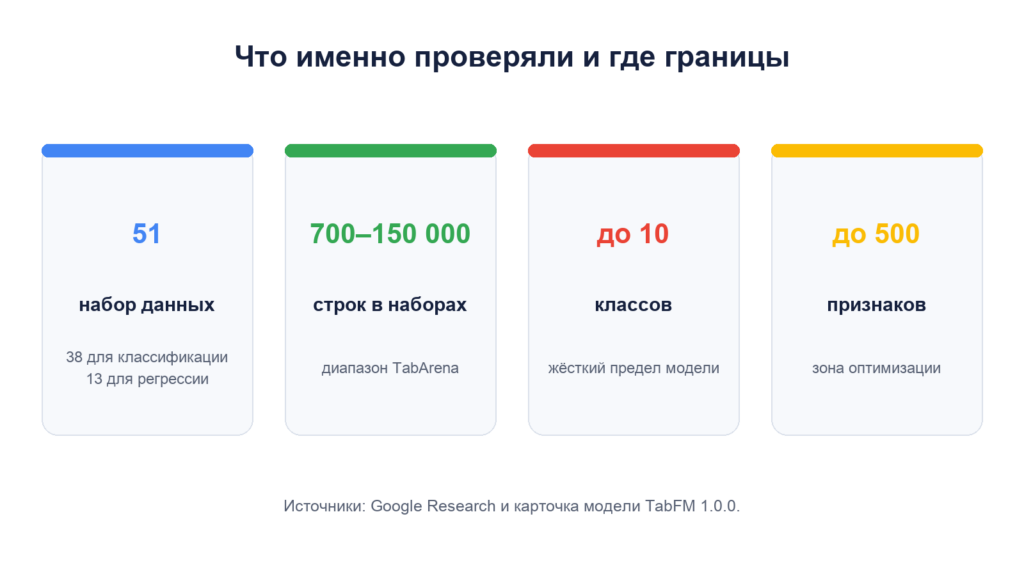
Google оценила модель на открытом бенчмарке TabArena: 38 наборах для классификации и 13 для регрессии, содержащих от 700 до 150 тысяч строк. Система рассчитывает рейтинг Elo по результатам попарных сравнений методов.
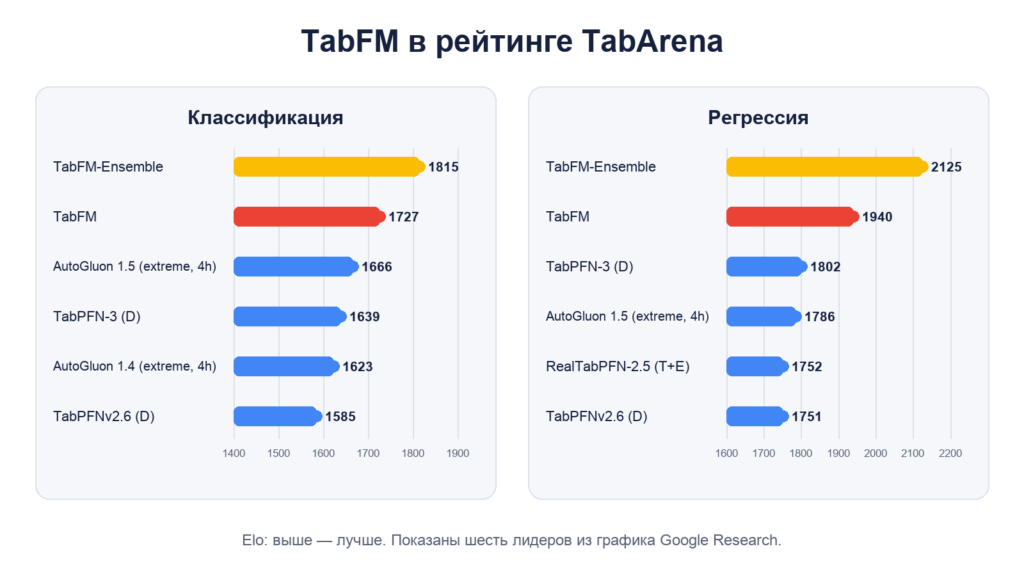
На опубликованном Google графике базовая TabFM получила 1727 баллов Elo в классификации и 1940 в регрессии, заняв второе место в обеих группах. Первой стала TabFM-Ensemble — 1815 и 2125 баллов соответственно.
Однако ансамблевый вариант нельзя приравнивать к самому простому запуску. Он объединяет 32 конфигурации при помощи неотрицательных наименьших квадратов, добавляет перекрёстные и SVD-признаки, а в классификации — калибровку Платта. Базовая TabFM делает прогноз одним прямым проходом без подбора настроек и кросс-валидации.
Elo — относительный показатель, а TabArena является обновляемым бенчмарком. Поэтому лидерство на одном срезе не доказывает превосходство на каждой бизнес-задаче. Как показывают и другие тесты ИИ-моделей на специализированных заданиях, итог зависит от состава данных, метрики и условий сравнения.
Где заканчивается обещание «без обучения»
- Нужны размеченные примеры. TabFM не угадывает задачу из пустоты: исторические строки с известными ответами входят в контекст.
- Память растёт вместе с контекстом. Все обучающие строки передаются модели во время инференса.
- Есть предел классов. Текущая версия поддерживает не более 10 классов.
- Очень широкие таблицы — зона риска. Модель оптимизирована для таблиц до 500 признаков; на более широких качество может снижаться.
- Высокорисковые решения требуют отдельной проверки. Google рекомендует оценивать модель на репрезентативной отложенной выборке перед применением.
Прогноз следует воспринимать как оценку вероятности, а не как гарантию. Недавний случай, когда 12 ИИ-моделей единогласно ошиблись в футбольном прогнозе, наглядно показывает разницу между правдоподобным расчётом и реальным исходом.
Открытый код, но не полностью открытые условия
Google опубликовала код TabFM на GitHub по лицензии Apache 2.0 и подготовила веса для JAX и PyTorch. При этом сами веса доступны по отдельной некоммерческой лицензии. В карточке также указано, что TabFM не является официально поддерживаемым продуктом Google.
Компания планирует встроить технологию в BigQuery. Согласно анонсу, в ближайшие недели пользователи должны получить возможность запускать классификацию и регрессию SQL-командой AI.PREDICT. До фактического появления функции это остаётся объявленным планом, а не уже доступной возможностью.
Что TabFM может изменить на практике
Главный потенциальный эффект — скорость первого прототипа. Аналитик сможет быстро проверить, есть ли в таблице сигнал для прогноза оттока, риска мошенничества, стоимости или спроса, прежде чем строить полноценный ML-пайплайн. Для небольших команд это может снизить порог входа в предиктивную аналитику.
Но финальное решение по-прежнему должно учитывать качество исходных данных, утечки целевой переменной, смещение выборки, стоимость ошибки и изменения во времени. TabFM убирает часть инженерной рутины; ответственность за корректную постановку задачи она не убирает.
Источники: анонс Google Research, репозиторий TabFM, карточка модели TabFM 1.0.0, бенчмарк TabArena.
Главное изображение создано искусственным интеллектом для Cifrum.kz и является концептуальной редакционной иллюстрацией. Графики и схемы подготовлены Cifrum.kz по данным указанных источников.




Комментарии к статье