


Маунтин-Вью, АҚШ. Google Research 30 маусымда кестелік деректерді жіктеу мен регрессияға арналған TabFM іргелі моделін таныстырды. Google зерттеу бөлімшесінің хабарлауынша, модель жаңа кестеде салмақтарын бөлек оқытпай, белгілерді қолмен құрастырмай және гиперпараметрлерді іріктемей жұмыс істей алады.
Бұл TabFM «мүлде оқытылмаған» дегенді білдірмейді. Модель алдын ала жүздеген миллион синтетикалық деректер жиынында оқытылған. Бұл жердегі zero-shot ұғымы нақты кестеге көшкенде модель параметрлері жаңартылмайтынын білдіреді: белгіленген мысалдар инференс кезінде тікелей контекст ретінде беріледі.
Неліктен кестелер ЖИ үшін әлі де күрделі
Сату, клиент өтінімдері, транзакциялар, қойма қалдықтары және тексеру нәтижелері көбіне мәтін немесе сурет емес, жолдар мен бағандар түрінде сақталады. Мұндай деректерде градиенттік бустинг, кездейсоқ орман және басқа арнайы алгоритмдер ұзақ уақыт бойы негізгі құрал болды.
Дәстүрлі жоба белгілерді таңдап, бос мәндер мен санаттарды өңдеуді, бірнеше модельді оқытып, баптауды және нәтижені бөлек іріктемеде тексеруді талап етеді. TabFM осы циклді қысқартуды көздейді: бір алдын ала оқытылған модель жаңа міндеттің заңдылығын белгілі жауаптары бар мысалдардан анықтауы керек.
| Кезең | Дәстүрлі кестелік ML | TabFM |
|---|---|---|
| Міндетті дайындау | Әр жиынға жеке пайплайн | Оқу жолдары контекст ретінде беріледі |
| Модель параметрлері | Оқыту кезінде өзгереді | Жаңа кестеде өзгермейді |
| Баптау | Гиперпараметрлерді іздеу жиі қажет | Негізгі режим — бір тікелей өту |
| Сапаны тексеру | Міндетті | Сондай-ақ міндетті |
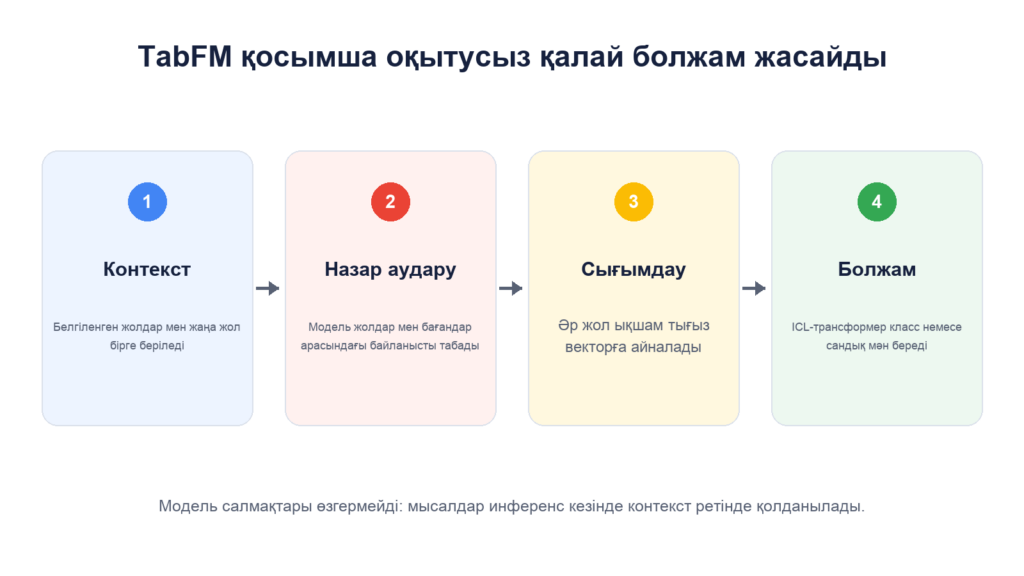
Модель жолдар мен бағандарды қалай оқиды
TabFM кестенің белгіленген бөлігін және жауап қажет жолдарды біртұтас кіріс ретінде қабылдайды. Архитектураның алғашқы блогы назар аударуды бағандар мен жолдар арасында кезекпен қолданады: модель белгілер арасындағы байланысты және мысалдардың ұқсастығын іздейді.
Содан кейін әр жол туралы ақпарат тығыз векторлық көрініске сығымдалады. Соңғы блок — 24 қабатты себептік ICL-трансформер — осы векторлардың тізбегін өңдеп, класс немесе сандық мән береді. TabFM 1.0.0 модель карточкасына сәйкес, архитектура сандық және санаттық бағандарды қолдайды.
Scikit-learn-мен үйлесімді интерфейсте fit() әдісі әлі де қолданылады. Бірақ TabFM ресми репозиторийі бұл шақыру іргелі модель параметрлерін қайта оқытпай, санат кодтағыштары мен сандық масштабтауды дайындайтынын көрсетеді.
Неліктен синтетикалық кестелер таңдалды
Мәтіндік және визуалды модельдер үшін ірі ашық жинақтар бар, ал өнеркәсіптік кестелер көбіне коммерциялық схемалар мен жеке деректерді қамтиды. Google бұл тапшылықты құрылымдық себептік модельдер көмегімен жүздеген миллион синтетикалық жиынды динамикалық түрде генерациялау арқылы айналып өтті.
Бұл тәсіл нақты клиенттік базаларды пайдаланбай, модельге белгілер арасындағы көптеген тәуелділікті көрсетуге мүмкіндік береді. Дегенмен синтетикалық орта нақты саладағы сирек оқиғаларды, мінез-құлықтың өзгеруін немесе ығысуларды толық қайталайтынына кепілдік бермейді.
TabArena рейтингі нені көрсетті
Google модельді ашық TabArena бенчмаркінде бағалады: жіктеуге арналған 38 және регрессияға арналған 13 деректер жиыны, олардың көлемі 700-ден 150 мың жолға дейін. Жүйе әдістерді жұппен салыстыру нәтижесі бойынша Elo рейтингін есептейді.
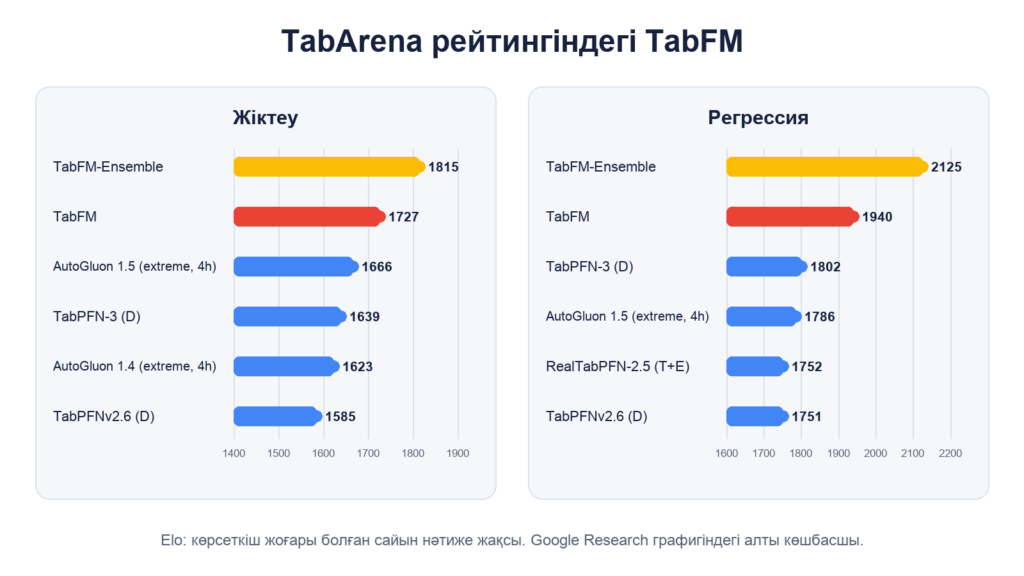
Google жариялаған графикте негізгі TabFM жіктеуде 1727, регрессияда 1940 Elo ұпайын алып, екі топта да екінші орынға шықты. TabFM-Ensemble нұсқасы тиісінше 1815 және 2125 ұпаймен бірінші болды.
Бірақ ансамбльдік нұсқаны қарапайым іске қосумен теңестіруге болмайды. Ол 32 конфигурацияны теріс емес ең кіші квадраттар әдісімен біріктіреді, қиылысқан және SVD белгілерін, ал жіктеуде Платт калибрлеуін қолданады. Негізгі TabFM баптаусыз және кросс-валидациясыз бір тікелей өтуде болжам жасайды.
Elo — салыстырмалы көрсеткіш, ал TabArena үнемі жаңарып отырады. Сондықтан бір кесіндідегі көшбасшылық әр бизнес міндетінде үздік нәтиже болатынын дәлелдемейді. ЖИ модельдерінің арнайы сынақтарындағы сияқты, нәтиже деректер құрамына, метрикаға және салыстыру шарттарына тәуелді.

«Оқытусыз» уәдесінің шегі қайда
- Белгіленген мысалдар қажет. TabFM міндетті бос жерден таппайды: белгілі жауаптары бар тарихи жолдар контекстке кіреді.
- Жад шығыны контекстпен бірге өседі. Оқу жолдарының барлығы инференс кезінде модельге беріледі.
- Класс саны шектеулі. Қазіргі нұсқа ең көбі 10 класты қолдайды.
- Өте кең кестелер тәуекел аймағында. Модель 500 белгіге дейінгі кестелерге оңтайландырылған.
- Жоғары тәуекелді шешімдер жеке тексеруді талап етеді. Модельді нақты міндетке ұқсас бөлек деректерде бағалау қажет.
Болжамды кепілдік емес, ықтималдық бағасы ретінде қарастырған жөн. 12 ЖИ моделінің футбол нәтижесін болжауда бірдей қателесуі қисынды есеп пен нақты оқиға арасындағы айырмашылықты айқын көрсетті.
Код ашық, бірақ пайдалану шарттары толық ашық емес
Google TabFM кодын GitHub-та Apache 2.0 лицензиясымен жариялап, JAX және PyTorch салмақтарын ұсынды. Ал модель салмақтары жеке коммерциялық емес лицензиямен беріледі. Карточкада TabFM Google ресми түрде қолдайтын өнім емес екені де көрсетілген.
Компания технологияны BigQuery-ге енгізуді жоспарлап отыр. Анонсқа сәйкес, алдағы апталарда пайдаланушылар жіктеу мен регрессияны AI.PREDICT SQL командасымен іске қоса алуы тиіс. Функция нақты қолжетімді болғанға дейін бұл әзірше жарияланған жоспар болып қалады.
TabFM тәжірибеде нені өзгерте алады
Негізгі ықтимал әсері — алғашқы прототиптің жылдамдығы. Талдаушы толық ML-пайплайн құрмас бұрын кестеде клиенттің кетуін, алаяқтық тәуекелін, бағаны немесе сұранысты болжауға жеткілікті белгі бар-жоғын тез тексере алады. Бұл шағын командалар үшін болжамдық аналитикаға кіру шегін төмендетуі мүмкін.
Бірақ соңғы шешім бастапқы деректер сапасын, нысаналы айнымалының ағып кетуін, іріктеме ығысуын, қате құнын және уақыт бойынша өзгерісті ескеруі тиіс. TabFM инженерлік жұмыстың бір бөлігін азайтады, алайда міндетті дұрыс қою жауапкершілігін жоймайды.
Дереккөздер: Google Research анонсы, TabFM репозиторийі, TabFM 1.0.0 модель карточкасы, TabArena бенчмаркі.
Басты сурет Cifrum.kz үшін жасанды интеллект көмегімен жасалған тұжырымдамалық редакциялық иллюстрация. Графиктер мен схемаларды Cifrum.kz аталған дереккөздердің мәліметтері бойынша әзірледі.




Мақалаға пікірлер