

Ollama позволяет запускать языковые модели на собственном компьютере: запросы к локальной модели обрабатываются без передачи текста в сторонний облачный чат. В этой инструкции установим Ollama на macOS или Windows, запустим первую модель, проверим API и при желании добавим графический интерфейс Open WebUI.
Актуально на 21 июня 2026 года. Последний стабильный релиз — Ollama v0.30.10, опубликованный 17 июня. Интерфейс и команды могут измениться в будущих версиях.
Что такое Ollama и зачем она нужна
Ollama — бесплатный инструмент для загрузки и локального запуска открытых моделей. В официальной библиотеке доступны Qwen, Llama, DeepSeek, Gemma, Mistral и другие семейства. Ollama управляет файлами моделей, использует доступное ускорение GPU и предоставляет локальный API по адресу http://localhost:11434.
После загрузки локальной модели интернет для обычного диалога не нужен. Однако он требуется для установки, обновлений и скачивания моделей. Кроме того, в Ollama существуют облачные модели: если конфиденциальность принципиальна, выбирайте именно локальный тег модели и проверяйте, где выполняется запрос.
Системные требования: сколько памяти понадобится
Официальная документация задаёт требования к операционной системе и совместимости GPU, но не устанавливает универсальный минимум RAM или VRAM. Потребление памяти зависит от размера модели, квантования и длины контекста. Поэтому таблица ниже — практический ориентир, а не гарантия производительности.
| Конфигурация | С чего начать | Комментарий |
|---|---|---|
| 8 ГБ RAM | llama3.2:1b или llama3.2:3b | Подходит для знакомства; закройте тяжёлые приложения |
| 16 ГБ RAM / unified memory | qwen3:4b, иногда qwen3:8b | Практичный минимум для компактных моделей |
| 32 ГБ | Модели 8B–14B | Больше запаса для контекста и параллельных программ |
| 32–64 ГБ и больше | qwen3:30b, qwen3-coder:30b | Файл модели занимает около 19 ГБ, но нужен дополнительный запас памяти |
- macOS: требуется macOS Sonoma 14 или новее. Apple Silicon использует GPU через Metal и общую память; Intel Mac поддерживается в CPU-режиме.
- Windows: требуется Windows 10 22H2 или новее. Установщик работает без прав администратора.
- NVIDIA: по официальному списку совместимости нужны compute capability 5.0+ и актуальный драйвер; для новых версий документация указывает драйвер 531+.
- Диск: Windows-установке требуется не менее 4 ГБ, а модели занимают от сотен мегабайт до десятков и сотен гигабайт.
Шаг 1. Установка Ollama на macOS
Самый понятный способ — открыть официальную страницу загрузки, скачать Ollama.dmg, перенести приложение в папку Applications и запустить его. При первом запуске Ollama предложит добавить команду ollama в системный PATH.
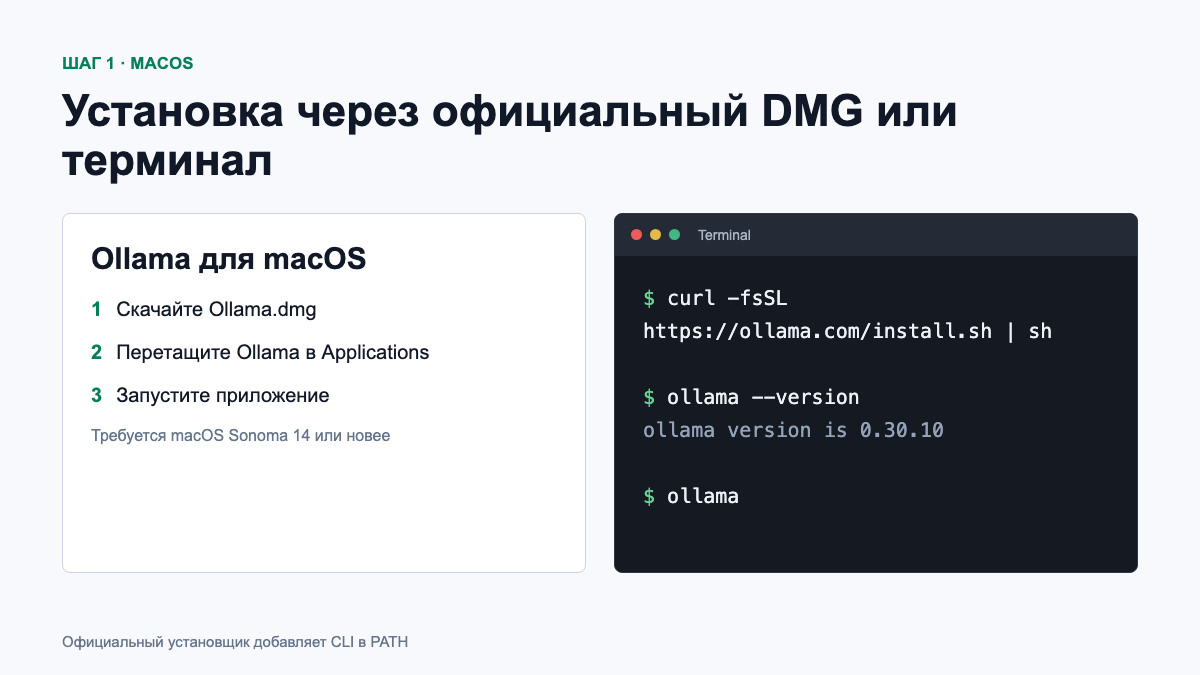
Альтернативный официальный способ — установка одной командой:
curl -fsSL https://ollama.com/install.sh | shЧерез Homebrew Ollama тоже доступна, но это пакет стороннего менеджера. Если вы уже используете Homebrew:
brew install ollamaПосле установки закройте и снова откройте Terminal, затем проверьте версию:
ollama --versionШаг 2. Установка Ollama на Windows
На Windows рекомендуется скачать OllamaSetup.exe с официальной страницы. В релизе v0.30.10 файл занимает около 1,3 ГБ. Установщик не требует прав администратора и по умолчанию размещает программу в домашнем каталоге пользователя.

Официальная установка через PowerShell:
irm https://ollama.com/install.ps1 | iexПосле завершения откройте новое окно PowerShell и выполните:
ollama --versionКак перенести модели на другой диск
Если на диске C мало места, откройте «Изменение переменных среды для учётной записи», создайте переменную OLLAMA_MODELS и укажите, например, D:\OllamaModels. После сохранения полностью закройте Ollama в системном трее и запустите снова. Этот порядок описан в документации Ollama для Windows.
Установка на Linux
Для большинства Linux-систем официальный проект предлагает тот же установочный скрипт:
curl -fsSL https://ollama.com/install.sh | shПосле установки проверьте службу командами ollama --version и systemctl status ollama. Для NVIDIA, AMD и экспериментального Vulkan сверяйтесь с актуальной страницей аппаратной поддержки.
Шаг 3. Скачайте и запустите первую модель
Команда ollama run сначала скачивает модель, а затем открывает интерактивный чат. Для компьютера с 8 ГБ RAM безопаснее начать с компактной Llama 3.2:
ollama run llama3.2:3bДля 16 ГБ памяти можно попробовать qwen3:4b, а при достаточном запасе — qwen3:8b:
ollama run qwen3:4b
ollama run qwen3:8b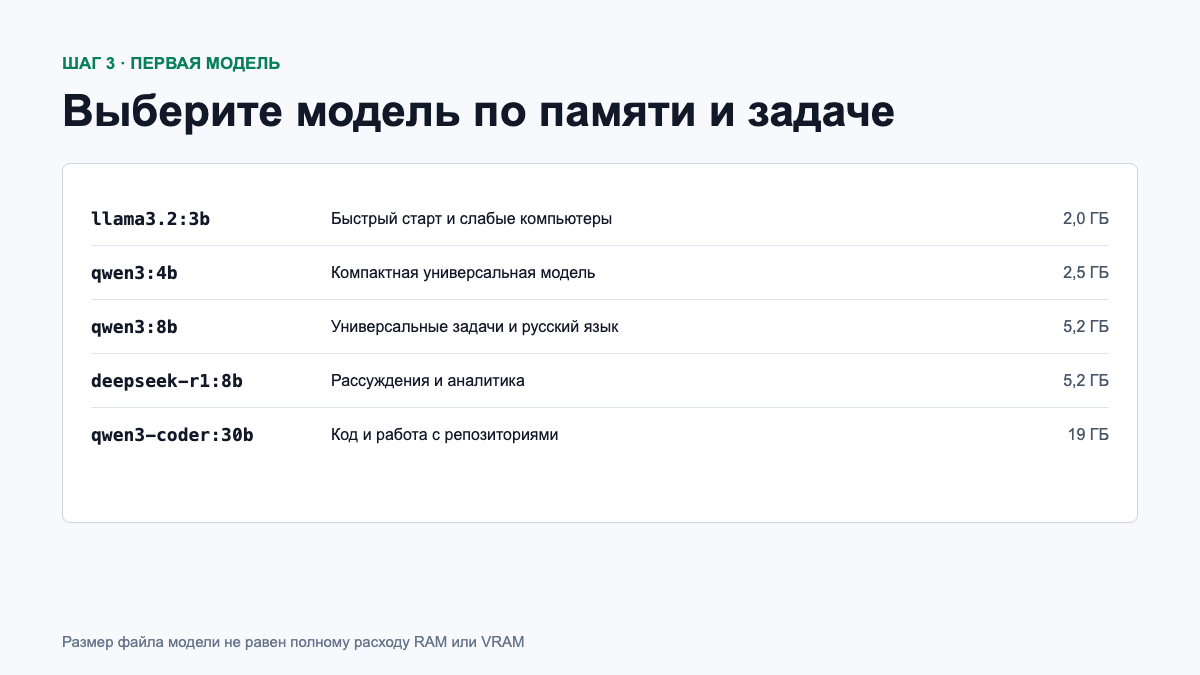
Введите вопрос после приглашения >>>. Для выхода используйте /bye или сочетание Ctrl+D. Полезные команды:
ollama list
ollama ps
ollama pull qwen3:8b
ollama rm qwen3:8bollama list— показать скачанные модели.ollama ps— показать модели, загруженные в память.ollama pull— скачать или обновить модель.ollama rm— удалить модель с диска.
Какие модели выбрать в июне 2026 года
| Модель | Размер загрузки | Подходит для |
|---|---|---|
llama3.2:3b | 2,0 ГБ | Первый запуск, суммаризация, простые задачи |
qwen3:4b | 2,5 ГБ | Компактный универсальный помощник |
qwen3:8b | 5,2 ГБ | Тексты, анализ, многоязычные задачи |
deepseek-r1:8b | 5,2 ГБ | Рассуждения, математика и аналитика |
qwen3:30b | 19 ГБ | Более сложные универсальные задачи |
qwen3-coder:30b | 19 ГБ | Программирование и работа с большим контекстом |
Размеры взяты из официальных карточек Qwen 3, Qwen3-Coder, DeepSeek-R1 и Llama 3.2. Это объём скачиваемых файлов, а не точное потребление оперативной памяти.
Шаг 4. Проверьте локальный API
Когда Ollama работает, API доступен локально на порту 11434. Проверка списка моделей:
curl http://localhost:11434/api/tagsПример одиночного запроса к модели:
curl http://localhost:11434/api/generate \
-d '{"model":"qwen3:4b","prompt":"Объясни, что такое локальная LLM","stream":false}'Шаг 5. Установите Open WebUI
Если терминал неудобен, Open WebUI добавляет интерфейс, похожий на привычный чат. Сначала установите Docker Desktop, затем выполните команду из официальной инструкции Open WebUI:
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
-v open-webui:/app/backend/data \
--name open-webui --restart always \
ghcr.io/open-webui/open-webui:main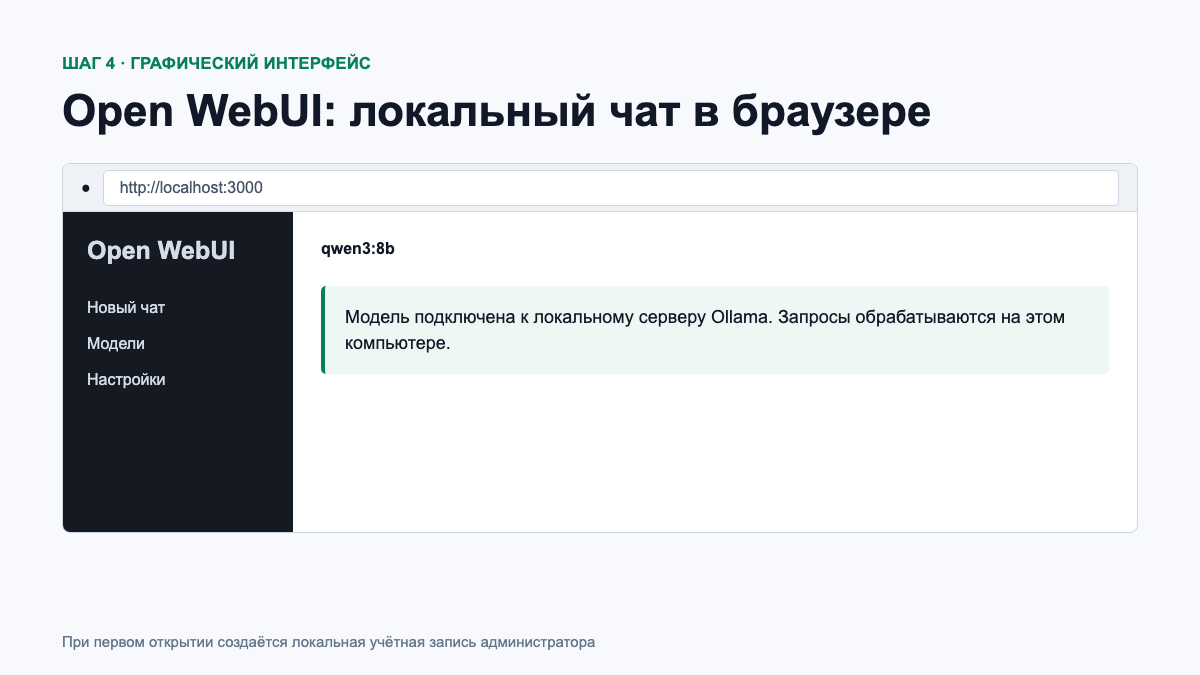
http://localhost:3000 и создайте локальную учётную запись администратора.Тег :main обновляется со временем. Для стабильной рабочей установки Open WebUI рекомендует закреплять конкретную версию образа. Также не открывайте порт 3000 в интернет без аутентификации, HTTPS и базовой защиты сервера.
Что делать, если Ollama не работает
- Команда не найдена: перезапустите терминал; на macOS проверьте наличие ссылки в
/usr/local/bin. - Модель работает слишком медленно: выберите меньшую модель, уменьшите контекст и закройте приложения, занимающие память.
- Используется CPU вместо GPU: обновите драйвер и сверьте видеокарту с официальным списком поддержки.
- Не хватает места: удалите ненужные модели через
ollama rmили перенесите каталог моделей. - Open WebUI не видит Ollama: проверьте, отвечает ли
http://localhost:11434/api/tags, и правильно ли заданOLLAMA_BASE_URL.
FAQ
Ollama полностью бесплатна?
Сам инструмент бесплатен. У каждой модели есть собственная лицензия, которую нужно проверить перед коммерческим использованием. Облачные функции также могут иметь отдельные условия.
Можно ли пользоваться Ollama без видеокарты?
Да, локальные модели могут работать на CPU, но генерация обычно заметно медленнее. Начните с модели 1B–3B.
Работает ли Ollama без интернета?
После установки и загрузки локальной модели — да. Интернет понадобится для скачивания и обновления моделей, а также для облачных функций.
Какая модель лучше для первого запуска?
Для 8 ГБ RAM начните с llama3.2:3b. Для 16 ГБ попробуйте qwen3:4b, а затем qwen3:8b, если система сохраняет достаточный запас памяти.
Вывод
Для первого знакомства достаточно установить Ollama официальным способом, проверить ollama --version и запустить компактную модель. Не начинайте с 30B-моделей только потому, что они выглядят мощнее: небольшая модель, полностью помещающаяся в доступную память, часто даёт более удобный и быстрый локальный опыт.
Обложка и пошаговые изображения созданы как обезличенные демонстрационные экраны. Они не содержат реальных аккаунтов, ключей, домашних каталогов или иных персональных данных.




Комментарии к статье